Archive for December 28th, 2012
Granger Causality
Granger causality is one of several tools that are extensively used to figure out cause and effect (causal) relationship from data. However there are some strong assumptions on data that limits the applicability of the Granger causality which will be listed later. Let us now formally introduce this Causality test for a simple linear model.
Let 




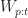


![X_{t+1}=\sum_{i=p}^{t}{\left\{\sum_{j=1}^{N}{\left[\alpha_{ij}*W_{ij}\right]} + \beta_i*X_i\right\}}](https://s0.wp.com/latex.php?latex=X_%7Bt%2B1%7D%3D%5Csum_%7Bi%3Dp%7D%5E%7Bt%7D%7B%5Cleft%5C%7B%5Csum_%7Bj%3D1%7D%5E%7BN%7D%7B%5Cleft%5B%5Calpha_%7Bij%7D%2AW_%7Bij%7D%5Cright%5D%7D+%2B+%5Cbeta_i%2AX_i%5Cright%5C%7D%7D+&bg=ffffff&fg=1c1c1c&s=0&c=20201002)
In the above equation, 

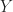
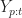
![\hat{X}_{t+1}=\sum_{i=p}^{t}{\left\{\sum_{j=1}^{N}{\left[\alpha_{ij}*W_{ij}\right]} + \beta_i*X_i + + \gamma_i*Y_i \right\}}](https://s0.wp.com/latex.php?latex=%5Chat%7BX%7D_%7Bt%2B1%7D%3D%5Csum_%7Bi%3Dp%7D%5E%7Bt%7D%7B%5Cleft%5C%7B%5Csum_%7Bj%3D1%7D%5E%7BN%7D%7B%5Cleft%5B%5Calpha_%7Bij%7D%2AW_%7Bij%7D%5Cright%5D%7D+%2B+%5Cbeta_i%2AX_i+%2B+%2B+%5Cgamma_i%2AY_i+%5Cright%5C%7D%7D+&bg=ffffff&fg=1c1c1c&s=0&c=20201002)
where 
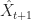


However, some of the caveats of the above method are:
- The linear system model assumption for the output variable
- The normality of the residuals from linear models. F-test is particularly sensitive to normality requirement. Non-normal residuals can skew the results from an F-test.
- Finally, the minimum number of data samples that are required to verify this causality could be significantly large depending on the number of control variables
of those control variables .
Pitfalls of Data Driven Models
Defining a system from data is poor mans version of research. If you don’t understand a complicated system, then throw in enough data and see if you could build a predictive model for your desired output variables from a series of control variables. More often what goes into the control variable pool is subjective but occasionally there is some reasoning behind it. Usually the reasoned part arises from the desire to reduce the volatility in predicting future values of the output variables. The belief here is that if by the addition of a new control variable to this cocktail pool of variables called the system model resulted in lowering the volatility in predicting future values of your output variables, then magically there is a cause and effect relationship between this new variable and your output variable. More often the researcher doesn’t elaborate on the basis of this causal relationship or at the best provides a perfunctory explanation that is often an excuse for his belief in this magical causality. This kind of data driven research leads to interesting set of conclusions some of which are listed in Nate Silver’s book Signals and Noise. However, the best example that I could find on the interwebs for failing to understand the dictum “correlation doesn’t imply causation” goes to the research by Tatu Westling of Universtiy of Helsinki who found an inverted-U relationship between the economic growth rates and reported average penis length. You may read about this interesting research here
Westling, T. (2011). Male organ and economic growth: Does size matter? University of Helsinki Discussion Paper (335).In the above article the author states the following “The existence and channel of causality remains obscure at this point but the correlations are robust” is the sort of reasoning that finally ends up in correlation masquerading as causality. However, this type of system modelling seems to be in vogue now. The 2003 Nobel prize from economics was won by C.W.J Granger for his contribution in analyzing time series data with common trends or Granger Causality and in 2011 the Nobel prize in economics was won by Christopher Sims for his contribution to the development of Vector Auto Regressive (VAR) for analyzing the cause of effect between statistical variables.
